Optimiser l'IA grâce aux data lakes : rôle et méthodes

Les projets d'intelligence artificielle en entreprise butent rarement sur un manque d'ambition. Ils échouent sur quelque chose de bien plus banal : des données mal organisées, incomplètes ou inexploitables. 70% des projets IA ne passent jamais le stade de la production à cause de problèmes de qualité des données. Le data lake, souvent présenté comme une solution miracle, reste pourtant mal compris par beaucoup d'équipes IT. Est-ce simplement un entrepôt géant, ou un vrai socle stratégique pour l'IA ? La réponse change tout à votre façon de l'architecturer.
Points Clés
| Point | Détails |
|---|---|
| Medallion structure | Organiser les données en couches bronze, argent et or optimise la fiabilité pour l'IA. |
| Importance de la qualité | La qualité des données est essentielle pour éviter l'échec en production IA. |
| Gouvernance data lake | Une gouvernance stricte des couches du data lake prévient les dérives et garantit l'utilisabilité. |
| Tests automatisés | Intégrer des tests automatisés réduit le risque de biais et d'erreurs dans l'exploitation de l'IA. |
Pourquoi un data lake est essentiel pour l'intelligence artificielle
L'intelligence artificielle est gourmande. Elle a besoin de volumes massifs de données variées, structurées ou non, pour apprendre, généraliser et produire des résultats fiables. Un data lake répond précisément à ce besoin en centralisant des données brutes issues de sources hétérogènes : logs applicatifs, fichiers CSV, flux d'événements, images, données CRM, capteurs IoT.
La différence fondamentale avec un data warehouse tient à la nature des données acceptées. Un data warehouse impose un schéma strict avant l'ingestion. Le data lake, lui, accepte tout en l'état, puis structure selon les besoins. Pour l'IA, cette flexibilité est décisive : un modèle de machine learning entraîné sur des données trop filtrées en amont risque de manquer des signaux importants.
Voici les atouts concrets du data lake pour les projets IA :
- Volumétrie sans contrainte : stocker des téraoctets de données historiques sans restructuration préalable
- Diversité des formats : JSON, Parquet, images, audio, texte libre, tout coexiste
- Accès multi-équipes : data scientists, ingénieurs data et analystes travaillent sur la même source
- Évolutivité : ajouter de nouvelles sources de données sans refondre l'architecture
- Compatibilité avec les systèmes multi-agents IA : les agents peuvent interroger des couches différentes selon leurs besoins
"L'approche medallion (bronze-argent-or) permet d'améliorer progressivement la structure et qualité des données."
Cette gradation est la clé qui transforme un data lake brut en infrastructure réellement utilisable par l'IA. Les intégrations IA HubSpot ou Pipedrive, par exemple, bénéficient directement d'un data lake bien structuré pour alimenter des modèles de scoring ou de recommandation en temps réel.
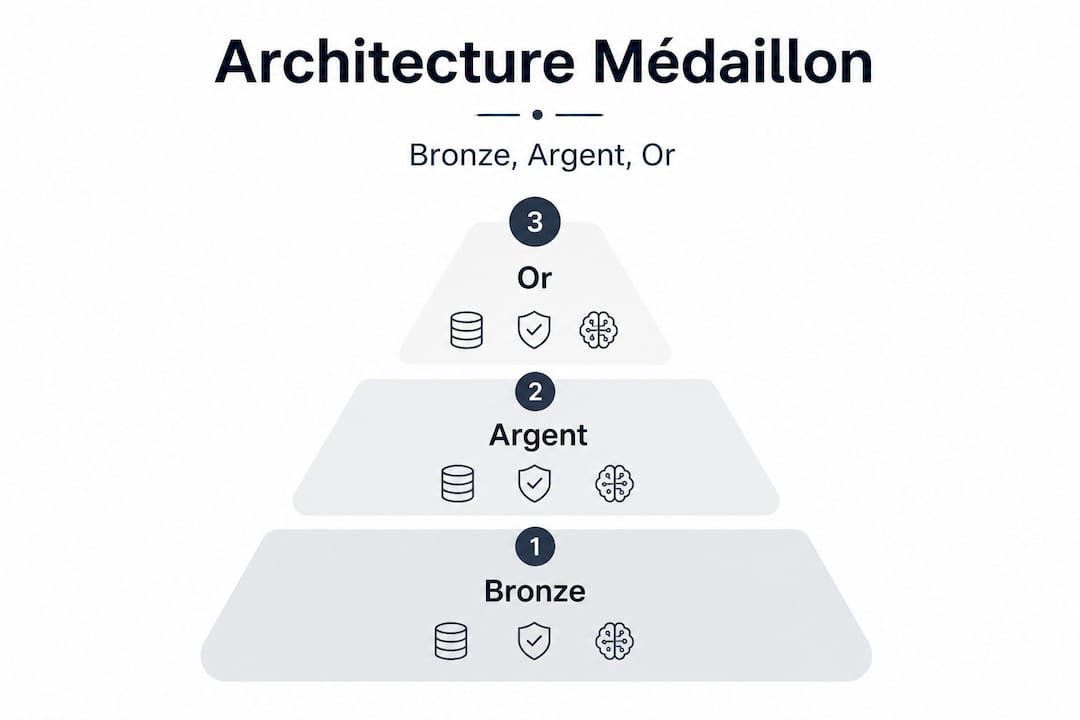
Architecture medallion : bronze, argent, or — organiser pour fiabilité
L'architecture medallion est aujourd'hui la référence pour structurer un data lake orienté IA. Elle divise le stockage en trois couches successives, chacune représentant un niveau de maturité des données. Microsoft Fabric recommande cette approche pour organiser la donnée dans OneLake, avec l'objectif d'améliorer incrémentalement structure et qualité.
Voici comment les trois couches fonctionnent en pratique :
-
Couche bronze (brute) : les données arrivent telles quelles, sans transformation. C'est la zone d'atterrissage. Aucune modification, aucun filtrage. Tout est conservé pour permettre la traçabilité et le rejeu en cas d'erreur.
-
Couche argent (nettoyée) : les données sont dédupliquées, normalisées et enrichies. Les erreurs évidentes sont corrigées. C'est ici que les règles métier de base s'appliquent. La plupart des pipelines de machine learning s'alimentent à cette couche.
-
Couche or (agrégée) : les données sont prêtes pour la consommation finale. Tableaux de bord, modèles IA en production, rapports décisionnels. La qualité est maximale, la latence minimale.
| Couche | Qualité des données | Usage principal | Exemples d'outils |
|---|---|---|---|
| Bronze | Brute, non validée | Archivage, audit, rejeu | Apache Kafka, S3 |
| Argent | Nettoyée, normalisée | Entraînement ML, analyse | dbt, Spark |
| Or | Agrégée, fiable | IA en prod, BI, décision | Databricks, Synapse |
Le passage d'une couche à l'autre n'est pas automatique. Il nécessite des pipelines de transformation explicitement définis, testés et documentés. C'est précisément là que beaucoup d'équipes perdent du temps : elles ingèrent bien les données en bronze, mais négligent la transition vers argent, laissant les data scientists travailler sur des données semi-brutes.

Les petits modèles IA spécialisés, par exemple, tirent un avantage considérable d'une couche or bien construite : moins de bruit, meilleure précision, inférence plus rapide.
Conseil de pro : définissez dès le départ qui est responsable de chaque couche. Sans ownership clair, la couche argent devient un no man's land où personne ne se sent légitime pour corriger les anomalies. Cette confusion est l'une des causes les plus fréquentes de dégradation silencieuse de la qualité.
Qualité des données : prérequis pour une IA fiable
Un data lake mal gouverné devient rapidement un "data swamp", un marécage où les données s'accumulent sans valeur exploitable. La qualité des données n'est pas un détail de mise en œuvre. C'est la condition sine qua non de la fiabilité de vos modèles IA.
Les indicateurs clés à surveiller sont :
- Complétude : quel pourcentage de champs obligatoires est renseigné ?
- Taux d'erreur : combien d'enregistrements contiennent des valeurs aberrantes ou incohérentes ?
- Fraîcheur : les données sont-elles mises à jour selon le SLA défini ?
- Unicité : y a-t-il des doublons qui fausseraient l'entraînement ?
- Cohérence : les mêmes entités sont-elles représentées de façon identique entre sources ?
| Indicateur | Seuil recommandé | Impact sur l'IA si non respecté |
|---|---|---|
| Complétude | > 95% | Biais dans les prédictions |
| Taux d'erreur | < 2% | Dégradation de la précision |
| Fraîcheur | Selon SLA défini | Décisions sur données obsolètes |
| Unicité | > 99% | Surpondération de certains cas |
Des contrats de données et des tests automatisés peuvent réduire les risques de biais dus à des données incomplètes ou contradictoires. Un contrat de données est un accord formel entre producteurs et consommateurs de données : il définit le format attendu, la fréquence de livraison, les seuils de qualité et les responsabilités en cas de violation.
Les outils à intégrer dans votre pipeline de qualité :
- Great Expectations : définir des règles de validation et les exécuter automatiquement à chaque ingestion
- dbt tests : valider les transformations SQL avec des assertions sur les données résultantes
- Monte Carlo ou Soda : détecter les anomalies statistiques en continu
- Apache Atlas ou DataHub : gérer les métadonnées et la traçabilité
La fiabilité des agents IA en production dépend directement de cette rigueur. Un agent qui interroge une couche or contaminée par des données mal validées produira des réponses incorrectes, parfois sans signal d'erreur visible. Pour intégrer l'IA en entreprise avec succès, la qualité des données doit être traitée comme un projet à part entière, pas comme un prérequis implicite.
Déployer un data lake IA : étapes et conseils pratiques
Passer de l'intention à un data lake opérationnel pour l'IA demande une séquence précise. Beaucoup d'équipes IT commettent l'erreur de choisir la technologie avant de définir les usages. Résultat : une infrastructure coûteuse qui ne répond pas aux besoins réels des data scientists.
Voici les étapes clés pour un déploiement réussi :
-
Cartographier les sources de données : identifier toutes les sources existantes, leur format, leur fréquence de mise à jour et leur propriétaire métier. Cette cartographie révèle souvent des doublons et des lacunes insoupçonnés.
-
Définir les cas d'usage IA prioritaires : quel modèle voulez-vous entraîner en premier ? Quelles données sont strictement nécessaires ? Cette étape évite de tout ingérer sans discernement.
-
Choisir la plateforme de stockage : AWS S3, Azure Data Lake Storage, Google Cloud Storage ou une solution on-premise selon vos contraintes de souveraineté et de coût.
-
Implémenter l'architecture medallion : créer les trois couches dès le départ, même si seule la couche bronze est active initialement. Changer l'architecture en cours de route est coûteux.
-
Définir les règles de gouvernance : la structure en couches n'est pas automatique. Il faut des règles d'ownership, des SLA, des définitions et des contrôles d'accès pour chaque couche.
-
Automatiser les pipelines de qualité : intégrer Great Expectations ou dbt tests dans vos workflows CI/CD pour que chaque livraison de données soit validée avant de progresser vers la couche suivante.
-
Former les équipes et documenter : un data lake sans documentation devient rapidement opaque. Chaque dataset doit avoir un propriétaire, une description et un historique de modifications.
La gestion du cycle de vie des données est souvent négligée. Des données qui ne servent plus doivent être archivées ou supprimées selon une politique explicite. Conserver indéfiniment tout ce qui arrive en bronze fait exploser les coûts de stockage sans apporter de valeur.
Conseil de pro : surveillez les coûts de transfert entre zones de stockage et de calcul. Dans les architectures cloud, le vrai poste de dépense n'est souvent pas le stockage lui-même, mais les requêtes fréquentes sur de grands volumes en couche bronze. Partitionner intelligemment vos données dès l'ingestion peut réduire la facture de 40 à 60%.
Notre point de vue : ce que les architectures data lake oublient souvent
Après avoir accompagné de nombreuses équipes IT dans leurs projets data, nous avons observé un pattern récurrent. Les organisations maîtrisent la théorie de l'architecture medallion. Elles connaissent bronze, argent, or. Mais dans la pratique, la frontière entre les couches devient floue en quelques mois.
Pourquoi ? Parce que la pression opérationnelle pousse les équipes à court-circuiter les étapes. Un data scientist qui a besoin de données rapidement va directement en bronze, crée son propre pipeline de nettoyage ad hoc, et ce pipeline non documenté devient une dépendance cachée. Six mois plus tard, personne ne sait plus quelle version des données est la bonne.
La vraie valeur d'un data lake n'est pas dans sa capacité à stocker beaucoup. C'est dans sa capacité à évoluer sans casser ce qui existe. Et cela exige une gouvernance active, pas passive. Une gouvernance active, c'est des revues régulières des pipelines, des alertes sur les dérives de qualité, et surtout une culture où corriger un problème de données est aussi valorisé que livrer une nouvelle fonctionnalité IA.
Les coûts cachés sont une autre réalité que les équipes découvrent trop tard. La latence des requêtes sur des couches mal partitionnées, les coûts de calcul pour transformer des données mal structurées en bronze, les heures passées à déboguer des pipelines fragiles. Ces coûts ne figurent pas dans les présentations de lancement de projet.
Notre conviction : un data lake réussi se construit en itérant sur la gouvernance autant que sur la technologie. Commencez petit, avec deux ou trois sources de données bien maîtrisées, une couche or propre pour un seul cas d'usage IA, et des règles de qualité documentées. Puis étendez. Cette approche incrémentale produit des résultats bien plus durables que l'ingestion massive suivie d'une longue phase de nettoyage rétrospective.
Solutions BotiqueAI pour accélérer votre projet IA
Mettre en place un data lake fiable pour l'IA demande à la fois une expertise technique et une vision stratégique claire. Les bonnes pratiques décrites dans cet article, architecture medallion, contrats de données, gouvernance active, sont des fondations solides. Mais les traduire en réalité opérationnelle dans votre contexte spécifique est une autre étape.

BotiqueAI accompagne les équipes IT et les responsables data dans la conception et le déploiement de socles data adaptés à leurs projets IA. Que vous partiez de zéro ou que vous cherchiez à fiabiliser une architecture existante, nos solutions sur mesure couvrent l'ingestion, la transformation, la gouvernance et l'intégration avec vos modèles IA. Découvrez les solutions IA BotiqueAI disponibles ou visitez le site BotiqueAI pour échanger avec notre équipe sur vos enjeux data.
Foire aux questions
Quelle différence entre un data lake et un data warehouse pour l'IA ?
Un data lake stocke des données brutes, variées et massives, alors qu'un data warehouse organise des données structurées pour des usages spécifiques. Le data lake offre plus de flexibilité pour entraîner des modèles IA, notamment grâce à l'approche medallion qui améliore progressivement la structure et qualité des données.
Quelles actions garantissent la qualité des données pour l'IA ?
Il faut définir des contrats de données, poser des seuils de complétude ou d'erreur et utiliser des tests automatisés. Les contrats de données et tests automatisés réduisent les risques de biais dus à des données incomplètes ou contradictoires.
Comment éviter les dérives dans une architecture medallion ?
Mettez en place une gouvernance stricte avec des règles d'ownership, des SLA, des définitions et des contrôles d'accès pour chaque couche. La structure en couches n'est pas automatique et exige un cadre explicite pour rester fiable dans le temps.
Quels outils pour valider la qualité dans un data lake IA ?
Des outils comme Great Expectations ou dbt tests permettent de valider la qualité, la complétude et l'absence de biais avant d'utiliser les données en IA. Ces tests automatisés s'intègrent directement dans les pipelines CI/CD pour une validation continue à chaque ingestion.