Cloud-Native AI Deployment: A Guide for IT Teams
Cloud-Native AI Deployment: A Guide for IT Teams

Cloud-native AI deployment is the practice of building, running, and scaling AI applications using cloud-native technologies such as containers, Kubernetes, and microservices. The industry term for this approach is “AI-native infrastructure,” and it represents a fundamental shift from traditional, monolithic AI setups. Approximately 36% of cloud-native developers now run AI workloads on Kubernetes as of Q2 2026. That number signals a clear direction: the organizations moving fastest on AI are doing it on cloud-native foundations. For IT professionals and decision-makers, understanding what is cloud-native AI deployment means understanding the infrastructure decisions that determine whether AI projects reach production or stall in pilot.
What is cloud-native AI deployment and how does it work?
Cloud-native AI deployment uses containers, Kubernetes orchestration, and microservices architecture to package and run AI models the same way modern software applications are built. Each AI component, whether a model inference service, a data pipeline, or a feature store, runs as an isolated container. Kubernetes manages scheduling, scaling, and recovery across clusters. This architecture makes AI workloads portable across laptops, on-premises data centers, and public cloud environments without rebuilding the stack.
The core difference from traditional AI infrastructure is declarative management. Instead of manually configuring servers and dependencies, you define the desired state of your AI environment in code, and Kubernetes enforces it. This removes entire categories of configuration drift and environment mismatch that plague traditional deployments.

Containers and microservices for AI components
Containers solve one of the oldest problems in AI operations: the “it works on my machine” failure. Treating AI models as containerized workloads improves consistency from development to production. A container bundles the model, its dependencies, and its runtime into a single portable unit. Microservices architecture then lets you update the inference layer without touching the data preprocessing service, reducing deployment risk significantly.
Kubernetes orchestration and the Kubernetes AI Conformance program
Kubernetes is the control plane for cloud-native AI. Kubernetes 1.34 supports production-ready GPU and accelerator hardware scheduling with fine-grained dynamic resource allocation. That matters because AI workloads are GPU-hungry and expensive to over-provision. The Kubernetes AI Conformance program, established through the Cloud Native Computing Foundation (CNCF), defines multi-dimensional platform maturity standards for production-grade AI deployments. Platforms that meet this standard deliver verified interoperability and production readiness.
Serverless and autoscaling for dynamic AI inference
Serverless AI on Kubernetes scales model inference to zero when idle and spins up on demand. Knative’s graduation to production-ready status enables this pattern without vendor lock-in. For organizations running batch inference or low-traffic AI services, scaling to zero eliminates idle GPU costs entirely. Autoscaling also handles traffic spikes without manual intervention, which matters when AI services are customer-facing.
Pro Tip: Start with Kubernetes namespaces to isolate AI workloads from other services. This gives you cost visibility per project from day one, before you need a full chargeback model.
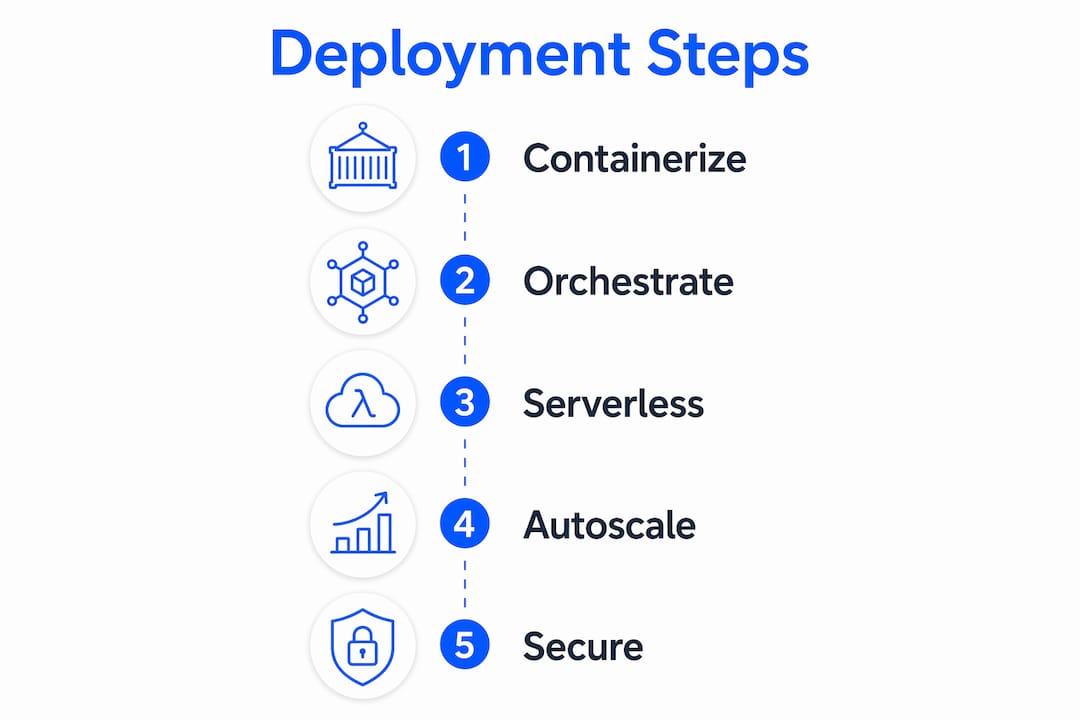
How cloud-native AI solves traditional infrastructure challenges
Traditional AI infrastructure creates four recurring problems: operational complexity, poor reproducibility, vendor lock-in, and unpredictable costs. Cloud-native approaches address each one directly.
-
Operational complexity. Manual AI infrastructure setup can take six weeks. Kubernetes-native platforms reduce that setup time to under 20 minutes by automating driver installation, GPU partitioning, and service mesh configuration. That is not a marginal improvement. It is the difference between a team that ships AI features quarterly and one that ships them weekly.
-
Reproducibility and portability. Containerized AI models resolve reproducibility and portability challenges that have long blocked AI teams from moving models from research to production reliably. The same container image that a data scientist runs locally deploys identically in a production cluster.
-
Vendor lock-in. Vendor-neutral cloud-native infrastructure built on CNCF-supported standards lets you move AI workloads between AWS, Azure, Google Cloud, and on-premises environments without rewriting your stack. Building on proprietary managed AI services creates dependency that is expensive to unwind later.
-
Cost control. GPU compute is the largest cost driver in AI infrastructure. Dynamic resource allocation through Kubernetes prevents GPU over-provisioning. Scaling to zero for serverless inference eliminates idle costs. Both mechanisms require cloud-native architecture to function.
“Avoiding hyperscaler lock-in is critical. Building portable, composable AI stacks across cloud or on-premises environments ensures the flexibility organizations need as AI requirements evolve.” — CNCF Engineering Blog
Security is the fifth challenge that cloud-native AI introduces rather than inherits. Autonomous AI agents and model inference endpoints expand the attack surface beyond what traditional perimeter security covers. Production-ready cloud-native AI requires integrated security at the workload level, not bolted on afterward.
Common architectures, tools, and frameworks for cloud-native AI
The practical implementation of cloud-based AI deployment relies on a set of well-established tools and patterns. The table below maps the key architectural layers to the technologies that serve them.
| Architectural layer | Common tools and standards | Primary function |
|---|---|---|
| Container runtime | Docker, containerd | Package and run AI model containers |
| Orchestration | Kubernetes 1.34+ | Schedule, scale, and manage AI workloads |
| Serverless inference | Knative | Scale-to-zero model serving |
| MLOps pipelines | Kubeflow, MLflow | Model training, versioning, and deployment |
| GPU scheduling | Kubernetes device plugins | Allocate GPU and accelerator resources |
| Observability | Prometheus, Grafana | Monitor inference metrics and costs |
| Standards body | CNCF, Kubernetes AI Conformance | Interoperability and production readiness |
Multi-cluster and multi-cloud patterns are increasingly common in enterprise AI deployments. Organizations run training workloads on GPU-optimized clusters while serving inference on cost-optimized clusters in a different region or cloud. Kubernetes federation and GitOps tools like Argo CD manage consistency across these environments.
The CNCF ecosystem has produced several projects that extend the Kubernetes API specifically for AI and machine learning. Kubeflow adds ML pipeline orchestration. KServe provides a standard interface for model serving. These projects let you build a cloud-native machine learning platform without depending on a single vendor’s proprietary tooling.
MLOps is the operational discipline that ties these tools together. It applies DevOps principles, such as version control, automated testing, and continuous deployment, to AI model lifecycles. Without MLOps practices, cloud-native AI infrastructure delivers the plumbing but not the process discipline that production AI requires.
Best practices for deploying AI workloads in cloud-native environments
Getting cloud-native AI deployment right in production requires more than installing Kubernetes. The following practices separate teams that run AI reliably from those that struggle with cost overruns and instability.
-
Automate infrastructure provisioning. Use Kubernetes-native tooling to automate GPU driver installation, node configuration, and service mesh setup. Manual provisioning reintroduces the six-week setup problem that cloud-native is designed to eliminate.
-
Implement GPU-aware scheduling. AI workloads require GPU-aware scheduling and memory management strategies that are fundamentally different from stateless microservices. Set resource requests and limits for GPU memory explicitly. Use node affinity rules to place large models on nodes with sufficient VRAM.
-
Build observability into the AI layer. Without observability of token throughput and cost metrics, AI deployments risk failing to maintain performance and cost balance at scale. Track inference latency, token throughput, and GPU utilization alongside standard infrastructure metrics. Prometheus and Grafana provide this visibility without additional licensing costs.
-
Version AI models like software. Use a model registry, such as MLflow’s model registry, to track model versions, their associated containers, and their deployment history. This makes rollback as simple as redeploying a previous container image.
-
Plan for setup complexity. Teams consistently underestimate the operational complexity of cloud-native AI. GPU drivers, CUDA versions, container runtimes, and Kubernetes versions must all align. Test this stack in a staging environment before production deployment.
-
Apply integrated security at the workload level. AI agents and inference endpoints need network policies, secrets management, and runtime security scanning. Treat each model container as a production service with its own security posture, not as a research artifact.
Pro Tip: Use Kubernetes resource quotas per namespace to cap GPU spending by team or project. This prevents a single runaway training job from consuming your entire GPU budget before anyone notices.
Key Takeaways
Cloud-native AI deployment succeeds when organizations combine Kubernetes orchestration, vendor-neutral standards, and GPU-aware operations into a single production-ready platform.
| Point | Details |
|---|---|
| Containers solve reproducibility | Packaging AI models as containers eliminates environment mismatch from development to production. |
| Kubernetes 1.34 enables GPU scheduling | Fine-grained dynamic resource allocation makes GPU cost control practical at scale. |
| Setup time drops dramatically | Kubernetes-native automation reduces AI infrastructure setup from six weeks to under 20 minutes. |
| Vendor neutrality protects flexibility | CNCF-aligned standards let you move AI workloads across clouds without rewriting your stack. |
| Observability is non-negotiable | Monitoring token throughput and cost metrics prevents performance and budget failures in production. |
The infrastructure bet most teams are getting wrong
The conversation about cloud-native AI in most organizations focuses on which cloud provider to use. That is the wrong question. The right question is whether your AI infrastructure is portable enough to survive a change in cloud strategy, a shift in GPU pricing, or a new regulatory requirement about data residency.
At Botiqueai, we have worked with organizations that built their AI stack entirely on a single hyperscaler’s managed services. When pricing changed or a new model architecture required different hardware, they were stuck. Migrating was expensive and slow. The teams that built on Kubernetes with CNCF-aligned tooling moved faster and spent less when conditions changed.
The Kubernetes AI Conformance program matters more than most IT teams realize. Platform maturity is not a checkbox. It is the difference between an AI deployment that holds up under production load and one that requires constant firefighting. I have seen teams skip conformance testing to ship faster, only to spend three times as long debugging GPU scheduling failures in production.
The ecosystem is moving quickly. Knative’s graduation to production-ready status and Kubernetes 1.34’s GPU scheduling improvements both landed in 2026. The CNCF community is producing new AI-specific projects faster than most enterprise teams can evaluate them. My recommendation: pick a small number of well-supported CNCF projects, get them working reliably, and resist the urge to adopt every new tool. Depth beats breadth in production AI infrastructure.
Vendor-neutral infrastructure is not just a technical preference. It is an organizational asset. The teams that own their AI stack, rather than renting it from a single provider, make faster decisions and carry less risk. That is the bet worth making.
— Botiqueai
How Botiqueai supports your cloud-native AI strategy
Botiqueai builds AI solutions designed to run in cloud-native environments from day one. Whether you need a custom AI agent, an intelligent chatbot, or an automated workflow integrated with your existing Kubernetes infrastructure, Botiqueai delivers production-ready implementations without the six-week setup overhead. The Aria AI chatbot deploys directly into your web or e-commerce environment with full observability and no vendor lock-in. For organizations ready to move from AI pilot to production at scale, Botiqueai’s AI solutions for business provide the architecture and expertise to get there. Reach out to discuss your deployment requirements.
FAQ
What is cloud-native AI deployment in simple terms?
Cloud-native AI deployment is the practice of running AI models using containers, Kubernetes, and microservices instead of traditional server-based infrastructure. It makes AI workloads portable, repeatable, and cost-efficient across any environment.
How does cloud-native AI differ from traditional AI deployment?
Traditional AI deployment relies on manually configured servers and fixed infrastructure, which creates reproducibility problems and high setup costs. Cloud-native AI uses declarative Kubernetes management and containers to automate provisioning and eliminate environment inconsistencies.
Why does GPU scheduling matter in cloud-native AI?
AI workloads consume GPU memory differently than standard applications, and without GPU-aware scheduling, clusters over-provision hardware and waste budget. Kubernetes 1.34 introduces fine-grained dynamic resource allocation to address this directly.
What is the Kubernetes AI Conformance program?
The Kubernetes AI Conformance program is a CNCF standard that defines multi-dimensional platform maturity requirements for production-grade AI deployments. Platforms that meet this standard deliver verified interoperability across cloud and on-premises environments.
How long does it take to set up cloud-native AI infrastructure?
Manual AI infrastructure setup typically takes six weeks. Kubernetes-native platforms that automate driver installation, GPU partitioning, and service mesh configuration reduce that time to under 20 minutes.