L'apprentissage automatique expliqué aux dirigeants d'entreprise
L’apprentissage automatique expliqué aux dirigeants d’entreprise

L’apprentissage automatique n’est pas une formule magique que l’on active et qui transforme une entreprise du jour au lendemain. C’est une réalité que beaucoup de responsables de PME et de grandes entreprises découvrent après avoir investi temps et budget dans un projet mal préparé. Comprendre comment fonctionne l’apprentissage automatique, c’est d’abord accepter que cette technologie repose sur des données, des itérations et une rigueur méthodologique que ni un logiciel, ni un prestataire ne peuvent remplacer à votre place. Ce guide vous explique les principes fondamentaux, les types d’apprentissage, le cycle de vie d’un projet, et les obligations légales à respecter pour réussir votre intégration.
Table des matières
- Comprendre le fonctionnement de base de l’apprentissage automatique
- Les principaux types d’apprentissage automatique adaptés aux entreprises
- Le rôle crucial des données et de leur préparation dans le succès de l’apprentissage automatique
- Le cycle de vie d’un projet d’apprentissage automatique : de l’entraînement au déploiement
- Les enjeux juridiques et réglementaires : garantir la conformité RGPD dans vos projets ML
- Pourquoi penser que l’apprentissage automatique est magique est une erreur stratégique
- Découvrez comment BotiqueAI peut accompagner votre entreprise dans l’intégration de l’apprentissage automatique
- Questions fréquemment posées
Points Clés
| Point | Détails |
|---|---|
| Cycle itératif et data-driven | L’apprentissage automatique fonctionne par cycles répétitifs d’essais, erreurs et corrections basés sur l’analyse des données. |
| Types variés d’apprentissage | Les modèles supervisés, non supervisés et par renforcement répondent à différents besoins d’entreprise. |
| Données au cœur du succès | La qualité et la préparation rigoureuse des données conditionnent la réussite des projets ML. |
| Respecter les règles RGPD | Le RGPD s’applique pleinement aux projets ML et impose une conformité complète. |
| Attentes réalistes indispensables | Le ML n’est pas magique, c’est une discipline nécessitant préparation, rigueur et suivi continu. |
Comprendre le fonctionnement de base de l’apprentissage automatique
Contrairement à un logiciel classique qui applique des règles écrites par des développeurs, une machine apprenante construit ses propres règles à partir des données qu’on lui fournit. C’est la distinction centrale. L’apprentissage automatique ajuste des paramètres à partir de données pour produire des prédictions sans règles explicites. En clair : vous ne lui dites pas quoi chercher, vous lui montrez des exemples et elle apprend à généraliser.
Le cycle d’apprentissage suit une logique précise et séquentielle :
- Collecte des données : rassembler les données brutes issues de vos systèmes (CRM, ERP, capteurs, historiques clients).
- Prétraitement : nettoyer, formater et structurer ces données pour qu’elles soient exploitables.
- Modélisation : choisir un algorithme adapté à votre problème (classification, régression, clustering).
- Entraînement : faire tourner l’algorithme sur vos données pour qu’il ajuste ses paramètres internes.
- Évaluation : mesurer la précision du modèle sur des données qu’il n’a jamais vues.
- Déploiement : intégrer le modèle validé dans vos processus métier.
- Surveillance : suivre ses performances en conditions réelles et corriger les dérives.
Ce cycle itératif d’essais et corrections est au cœur du fonctionnement du ML. Le modèle ne “comprend” rien au sens humain du terme. Il minimise une erreur mathématique, répète l’opération des milliers de fois, et converge vers une solution statistiquement utile. La fiabilité des agents IA en production dépend directement de la qualité de ce cycle.
Conseil de pro : ne confondez pas précision en entraînement et performance réelle. Un modèle qui atteint 98 % de précision sur vos données d’entraînement mais seulement 70 % en production souffre de surapprentissage. Consultez des stratégies d’optimisation de modèles ML pour éviter ce piège fréquent.
Les principaux types d’apprentissage automatique adaptés aux entreprises
Une fois le fonctionnement général compris, la question devient : quel type d’apprentissage correspond à votre problème ? Les trois modes principaux sont l’apprentissage supervisé, non supervisé et par renforcement. Chacun répond à des besoins business bien distincts.
Apprentissage supervisé Le modèle apprend à partir de données étiquetées, c’est-à-dire des exemples pour lesquels la bonne réponse est déjà connue. Vous alimentez le système avec des historiques de transactions frauduleuses et non frauduleuses : il apprend à distinguer les deux. Application directe en entreprise : détection de fraude, prédiction de churn, qualification automatique des leads, scoring de crédit.

Apprentissage non supervisé Ici, il n’y a pas de réponse connue à l’avance. Le modèle identifie lui-même des structures cachées dans vos données. Typiquement utilisé pour segmenter votre clientèle en groupes homogènes sans que vous définissiez ces groupes au préalable. C’est particulièrement utile pour la personnalisation marketing ou la détection d’anomalies.
Apprentissage par renforcement Un agent prend des décisions dans un environnement et reçoit des récompenses ou pénalités selon ses choix. C’est le type d’apprentissage derrière les systèmes de recommandation dynamiques et l’automatisation via apprentissage en logistique. Moins courant en PME, mais très puissant pour des décisions séquentielles complexes.
| Type d’apprentissage | Données requises | Usage typique en entreprise | Limite principale |
|---|---|---|---|
| Supervisé | Étiquetées (labellisées) | Prédiction, classification | Nécessite beaucoup de données labellisées |
| Non supervisé | Non étiquetées | Segmentation, détection d’anomalies | Résultats difficiles à interpréter |
| Par renforcement | Interactions et retours | Optimisation dynamique, recommandation | Complexité de mise en œuvre |
Les exemples d’automatisation en PME montrent que l’apprentissage supervisé reste le point d’entrée le plus accessible pour la majorité des entreprises françaises qui débutent avec le ML.
Le rôle crucial des données et de leur préparation dans le succès de l’apprentissage automatique
C’est ici que la plupart des projets ML déraillent. Pas à cause de l’algorithme choisi. À cause des données qui l’alimentent. Le succès dépend fortement de la qualité des données, du nettoyage et du choix du problème à résoudre. Un algorithme performant sur des données médiocres produit des résultats médiocres. C’est aussi simple que ça.
Avant même de penser à la modélisation, voici les étapes incontournables de préparation :
- Définir clairement la question business : “prédire quels clients vont partir dans les 30 prochains jours” est une question opérationnelle. “améliorer la satisfaction client” ne l’est pas.
- Éliminer les valeurs aberrantes : un âge client de 300 ans ou un montant de commande négatif biaiseront votre modèle.
- Gérer les valeurs manquantes : suppression, imputation par la moyenne, ou modélisation des données manquantes selon leur volume et leur importance.
- Normaliser les échelles : un algorithme qui reçoit des revenus en millions d’euros et des âges en dizaines doit travailler sur des échelles comparables.
- Équilibrer les classes : si 95 % de vos transactions sont légitimes et 5 % frauduleuses, le modèle peut apprendre à tout classer comme légitime et afficher 95 % de précision sans jamais détecter une fraude.
Conseil de pro : impliquez vos équipes métier dès la phase de préparation des données, pas seulement les data scientists. Ce sont elles qui savent pourquoi un champ est vide, si une valeur est une erreur de saisie ou un cas réel, et ce qu’un segment client signifie concrètement. Ce dialogue évite des mois d’itérations inutiles. Pour les entreprises qui n’ont pas d’expertise technique en interne, intégrer l’IA sans expertise technique reste tout à fait possible avec le bon accompagnement.
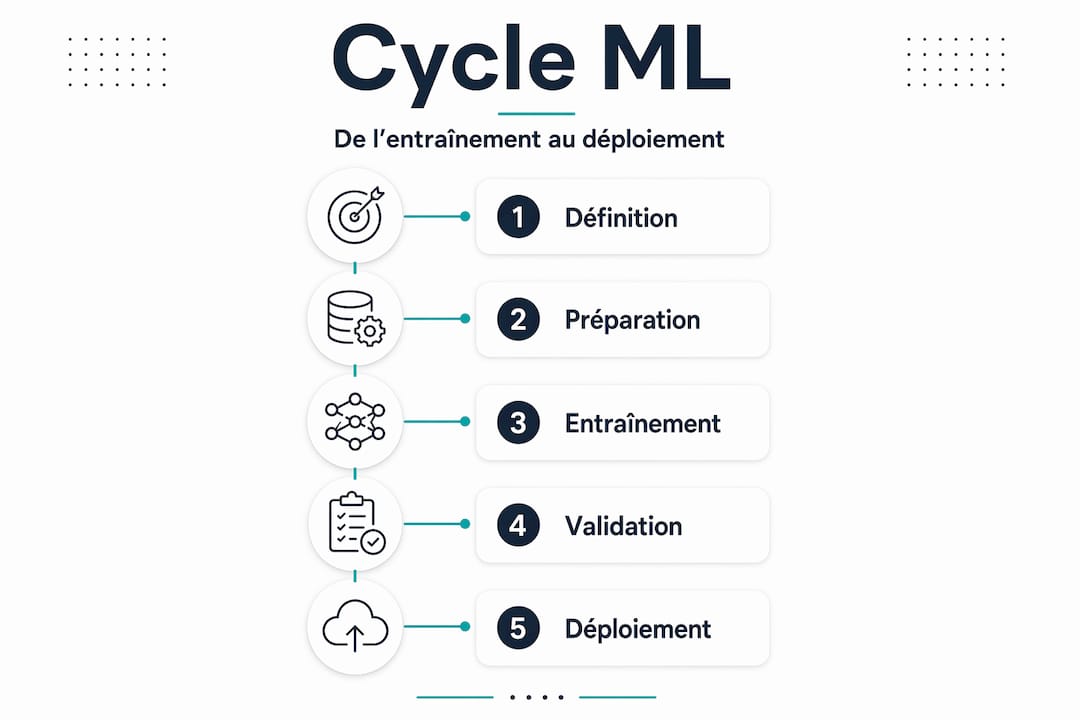
Le cycle de vie d’un projet d’apprentissage automatique : de l’entraînement au déploiement
Comprendre comment trainer un modèle d’apprentissage, c’est comprendre que le travail ne s’arrête pas quand le modèle est déployé. C’est là que beaucoup de responsables sont surpris. Le cycle complet inclut entraînement, évaluation, sélection, déploiement et suivi continu du modèle.
Voici les étapes séquentielles d’un projet ML mené de bout en bout :
- Définition du problème : traduire un enjeu business en problème mathématique mesurable.
- Collecte et nettoyage des données : rassembler les sources, identifier les biais, préparer les jeux d’entraînement et de test.
- Sélection du modèle : choisir parmi réseaux de neurones, arbres de décision, régressions ou méthodes ensemblistes selon le problème.
- Entraînement itératif : faire tourner le modèle, mesurer l’erreur, ajuster les hyperparamètres, recommencer.
- Validation croisée : tester sur plusieurs sous-ensembles de données pour garantir la robustesse.
- Déploiement : intégrer le modèle dans les systèmes existants via API ou conteneur.
- Surveillance continue : détecter les dérives de performance quand les données réelles changent.
Une mention spéciale pour l’AutoML : dans ce paradigme, plusieurs pipelines sont testés en parallèle et itérés jusqu’à atteindre les critères de sortie définis automatiquement. Cela accélère considérablement la phase de sélection de modèle pour des équipes sans data scientists dédiés.
| Étape | Outils courants | Responsable principal | Durée typique |
|---|---|---|---|
| Définition du problème | Ateliers, documentation | Direction métier | 1 à 2 semaines |
| Préparation des données | Python, SQL, dbt | Data engineer | 2 à 6 semaines |
| Entraînement et validation | Scikit-learn, Azure ML | Data scientist | 2 à 4 semaines |
| Déploiement | Docker, API REST | DevOps / IT | 1 à 3 semaines |
| Surveillance | Grafana, MLflow | Équipe IA | En continu |
L’automatisation du service client par IA illustre bien comment ce cycle, bien exécuté, produit des résultats mesurables et durables.
Les enjeux juridiques et réglementaires : garantir la conformité RGPD dans vos projets ML
Tout projet ML en France qui traite des données personnelles tombe sous le champ du RGPD. Sans exception. Le RGPD s’applique pleinement aux systèmes ML depuis la phase d’entraînement jusqu’à l’utilisation opérationnelle. Ignorer cette dimension, c’est s’exposer à des sanctions qui peuvent atteindre 4 % du chiffre d’affaires mondial.
Les obligations concrètes à anticiper :
- Définir une base légale : consentement, intérêt légitime ou exécution d’un contrat pour chaque traitement de données.
- Réaliser une analyse d’impact (AIPD) : obligatoire pour les traitements à risque élevé, notamment le profilage, la prise de décision automatisée ou le traitement de données sensibles.
- Respecter la minimisation : ne collecter que les données strictement nécessaires à l’objectif défini.
- Garantir la transparence : informer les personnes concernées de l’existence d’un système ML et de ses finalités.
- Appliquer le droit à l’explication : toute décision automatisée significative doit pouvoir être expliquée à la personne concernée.
- Mettre en œuvre des protections techniques : anonymisation, pseudonymisation, apprentissage fédéré (entraîner un modèle sans centraliser les données), confidentialité différentielle.
Les solutions IA conformes au RGPD ne sont pas un luxe réservé aux grandes entreprises. C’est une condition de base pour opérer légalement et bâtir la confiance de vos clients dans vos usages de l’IA.
Pourquoi penser que l’apprentissage automatique est magique est une erreur stratégique
Voici ce que personne ne vous dit clairement lors des présentations commerciales : la plupart des projets ML qui échouent en entreprise ne s’effondrent pas à cause d’un algorithme insuffisant. Ils s’effondrent parce que l’équipe dirigeante a sous-estimé le travail en amont.
La différence entre un modèle qui fonctionne en démo et un modèle utile en entreprise est la rigueur en amont : données nettoyées, questions bien formulées, sélection adaptée du modèle. Cette phrase résume une vérité que beaucoup de directions découvrent après avoir investi six mois et plusieurs dizaines de milliers d’euros dans un projet qui ne passe jamais en production.
Le discours marketing autour du ML crée des attentes qui ne correspondent pas à la réalité du terrain. On vous promet une IA qui “apprend toute seule” et s’améliore en continu. Techniquement, c’est possible. Pratiquement, l’IA n’apprend pas par intuition mais via ajustements progressifs. Ce cadre réaliste change radicalement la façon dont vous devez allouer votre budget : moins sur la technologie, plus sur la préparation des données et la définition des objectifs.
Il y a aussi le problème du compromis biais/variance. Un modèle trop simple ne capte pas les nuances de votre problème. Un modèle trop complexe mémorise vos données d’entraînement sans généraliser. Trouver le bon équilibre exige de l’expérience et des tests rigoureux, pas un paramètre magique.
Notre recommandation : avant de sélectionner une technologie ou un prestataire, définissez précisément ce que vous voulez mesurer pour valider le succès de votre projet ML. Un KPI clair comme “réduire de 15 % le taux de churn dans les 6 mois” protège votre investissement mieux que n’importe quel contrat. La réduction des coûts opérationnels avec l’IA est un objectif atteignable, mais seulement avec cette rigueur préalable.
Découvrez comment BotiqueAI peut accompagner votre entreprise dans l’intégration de l’apprentissage automatique
Passer de la compréhension théorique à une mise en œuvre concrète dans votre entreprise, c’est précisément là que l’accompagnement fait la différence. Chez BotiqueAI, nous travaillons avec des PME et de grandes entreprises françaises pour traduire leurs enjeux métier en projets ML opérationnels, sans jargon inutile et sans promesses irréalistes.

Nos solutions IA BotiqueAI couvrent l’intégralité du cycle : de la définition du problème à la surveillance en production. Que vous ayez besoin d’automatisations IA sur mesure pour vos processus internes ou d’un chatbot IA Shopify pour votre relation client, nos équipes conçoivent des outils adaptés à vos données, votre secteur et vos contraintes réglementaires. Chaque projet commence par un audit honnête de votre maturité data, parce qu’un bon partenaire vous dit ce qui est faisable avant de vous vendre ce qui est tendance.
Questions fréquemment posées
Qu’est-ce que l’apprentissage automatique et comment diffère-t-il de l’intelligence artificielle ?
L’apprentissage automatique est une sous-catégorie de l’IA dans laquelle les systèmes apprennent à partir de données et s’améliorent par l’expérience sans programmation explicite, tandis que l’IA au sens large englobe aussi des systèmes basés sur des règles codées manuellement.
Quels sont les principaux types d’apprentissage automatique ?
Les trois types principaux sont l’apprentissage supervisé (données labellisées), non supervisé (données sans étiquettes) et par renforcement (apprentissage par essais/erreurs avec récompenses).
Pourquoi la qualité des données est-elle si importante en apprentissage automatique ?
Parce que des données mal préparées ou non représentatives biaisent le modèle : le succès dépend fortement de la qualité des données et du nettoyage, même avec des algorithmes performants.
Comment garantir la conformité RGPD lors d’un projet d’apprentissage automatique ?
En appliquant les principes de finalité, minimisation et transparence, en réalisant une analyse d’impact pour les traitements à risque, et en utilisant des techniques comme l’anonymisation, car le RGPD s’applique pleinement depuis l’entraînement jusqu’à l’utilisation opérationnelle.
Quelles erreurs les entreprises commettent-elles souvent dans leurs projets ML ?
Elles sous-estiment le travail préalable sur les données et partent avec des objectifs vagues : la différence entre un modèle utile et un modèle de démo tient presque toujours à la rigueur de la préparation, pas à la puissance de l’algorithme.