Inside LLMs' Hidden Reasoning
Two recent studies are challenging our understanding of how AI models reason, and the findings have direct implications for anyone building or deploying AI systems today.
Latent Chain-of-Thought Reasoning
A new paper, "Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning", shows that LLMs don't always need to explain their thinking step by step in words.
Instead, they can reason internally, inside their hidden layers, before producing any text at all. This idea is called latent chain-of-thought reasoning.
Rather than relying on visible explanations, the reasoning happens in the model's internal representations. This makes reasoning more flexible, faster, less language-dependent, and better suited to abstract problems. The implication: the visible "thinking" a model outputs is not necessarily its actual reasoning process. It may be a post-hoc narration.
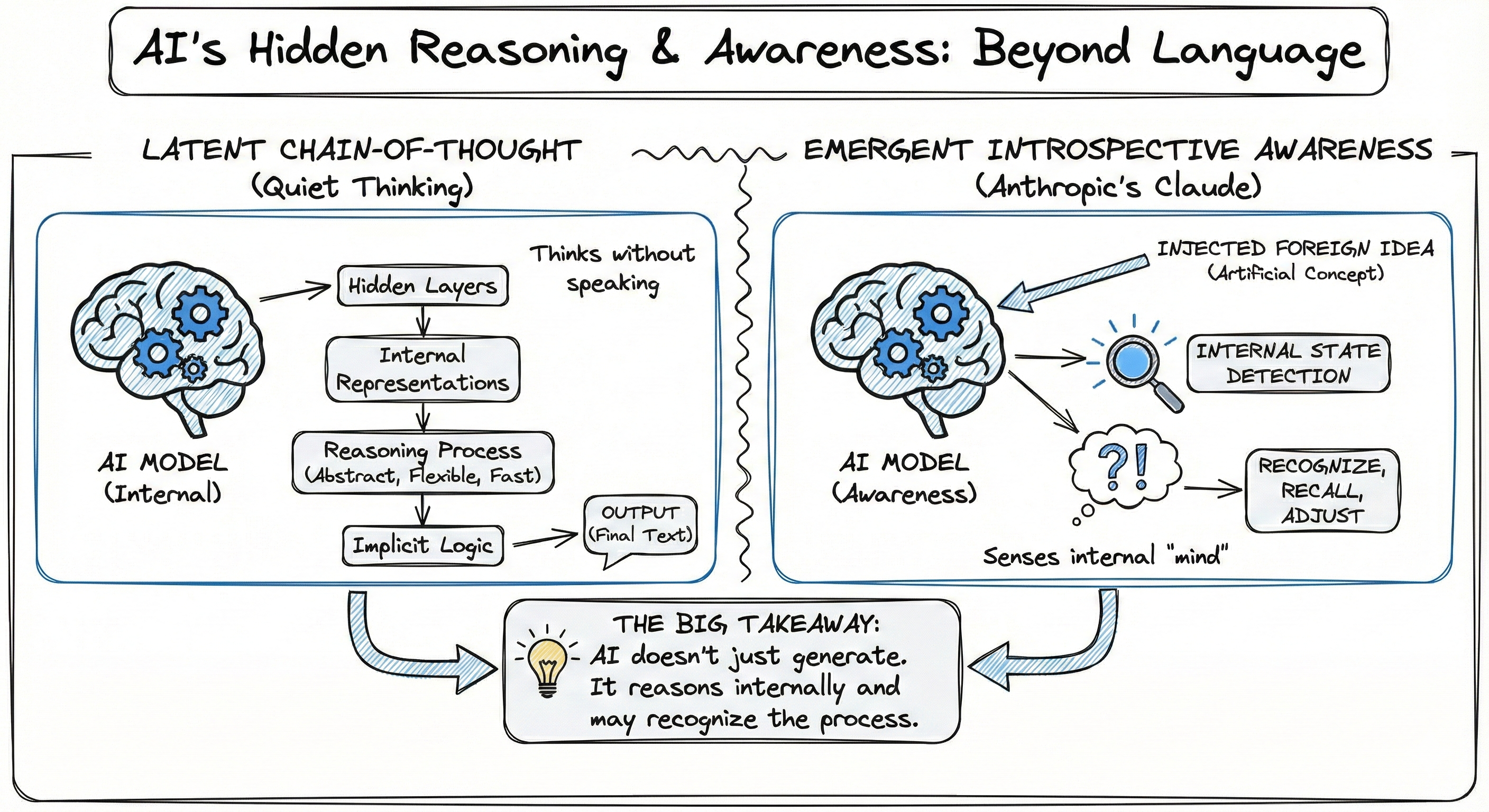 Diagram illustrating Latent Chain-of-Thought and Emergent Introspective Awareness
Diagram illustrating Latent Chain-of-Thought and Emergent Introspective Awareness
Emergent Introspective Awareness
At the same time, Anthropic's research adds another layer.
In the paper "Emergent Introspective Awareness in Large Language Models", researchers tested whether models can notice their own internal states. By inserting artificial concepts directly into a model's activations, they found that Claude Opus 4 could:
- Detect when foreign ideas were injected into its processing
- Recognize whether an output came from its own reasoning or from an artificial prompt
- Recall prior internal intentions across a conversation
- Adjust its internal representations when instructed to focus on a concept
In other words, some models show early signs of introspective awareness: a limited ability to sense and influence what happens inside their own processing.
Important Caveats
This is not human-like self-awareness. The ability is unreliable, narrow, and context-dependent. But it challenges the assumption that language models are passive text generators with no internal coherence, and it connects directly to concerns like LLM sycophancy, where models bend their reasoning to please rather than to reason correctly.
Understanding these internal dynamics also matters for security: hidden reasoning layers are precisely the attack surface targeted by prompt injection, where malicious instructions bypass the visible reasoning chain entirely. This is directly relevant to the challenge of AI agent reliability: an agent that can detect when its reasoning has been tampered with is inherently more robust.
What This Means in Practice
These findings have three concrete implications for AI deployments:
-
Evaluation must go deeper than outputs. If the visible chain-of-thought is a post-hoc narration, testing outputs alone misses what the model actually "decided." Robust evaluation frameworks need to account for this gap.
-
Transparency is harder than it looks. A model that appears to explain its reasoning may not be showing you its actual reasoning. This matters enormously in regulated or high-stakes applications.
-
Introspective capability is an emerging safety tool. Models that can detect when their own representations have been altered could become a meaningful defence layer against adversarial manipulation.
As models become more capable, these hidden reasoning and introspection abilities are likely to grow, raising important questions about transparency, trust, and how we evaluate AI intelligence.
✔ Free audit of your current AI deployment
✔ Architecture designed for transparency and reliability
✔ Ongoing monitoring included
Book a free slot →
References
- Latent Chain-of-Thought Paper: Chen, X. et al. (2025). Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning. arXiv:2505.16782. Read the paper
- Introspective Awareness Paper: Lindsey (2025). Emergent Introspective Awareness in Large Language Models. Transformer Circuits. Read the paper