Raisonnement Caché des LLMs : Chaîne de Pensée
Deux études récentes remettent en question notre compréhension du raisonnement des modèles IA, et leurs conclusions ont des implications directes pour quiconque conçoit ou déploie des systèmes d'intelligence artificielle aujourd'hui.
Le raisonnement latent par chaîne de pensée
Une nouvelle étude, "Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning", démontre que les LLMs n'ont pas toujours besoin d'expliquer leur raisonnement étape par étape en mots.
Ils peuvent raisonner en interne, dans leurs couches cachées, avant de produire le moindre texte. C'est ce qu'on appelle le raisonnement latent par chaîne de pensée (latent chain-of-thought reasoning).
Plutôt que de s'appuyer sur des explications visibles, le raisonnement se produit dans les représentations internes du modèle. Cela le rend plus flexible, plus rapide, moins dépendant du langage et mieux adapté aux problèmes abstraits. L'implication : la "réflexion" visible qu'un modèle produit n'est pas nécessairement son vrai processus de raisonnement. Elle peut n'être qu'une narration après coup.
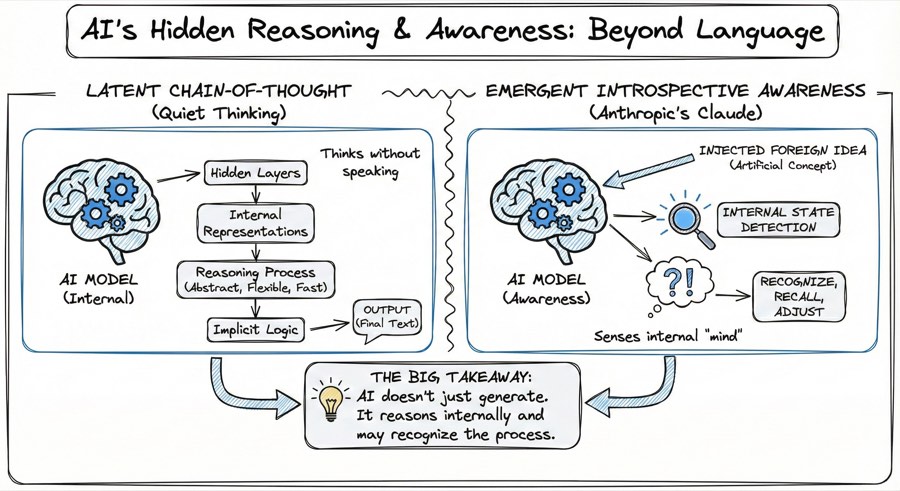 Illustration du raisonnement latent par chaîne de pensée et de la conscience introspective émergente
Illustration du raisonnement latent par chaîne de pensée et de la conscience introspective émergente
La conscience introspective émergente
En parallèle, la recherche d'Anthropic ajoute une nouvelle dimension.
Dans l'article "Emergent Introspective Awareness in Large Language Models", des chercheurs ont testé si les modèles peuvent percevoir leurs propres états internes. En injectant directement des concepts artificiels dans les activations d'un modèle, ils ont découvert que Claude Opus 4 pouvait :
- Détecter quand des idées étrangères avaient été injectées dans son traitement
- Reconnaître si une sortie provenait de son propre raisonnement ou d'un prompt artificiel
- Se souvenir d'intentions internes antérieures au fil d'une conversation
- Ajuster ses représentations internes quand on lui demandait de se concentrer sur un concept
En d'autres termes, certains modèles montrent des signes précoces de conscience introspective : une capacité limitée à percevoir et influencer ce qui se passe dans leur propre traitement.
Les nuances importantes
Il ne s'agit pas d'une conscience humaine. Cette capacité est peu fiable, limitée et dépendante du contexte. Mais elle remet en question l'idée que les modèles de langage sont de simples générateurs de texte sans cohérence interne, et elle rejoint directement les préoccupations liées à la sycophanie des LLMs, où les modèles infléchissent leur raisonnement pour plaire plutôt que pour raisonner correctement.
Comprendre ces dynamiques internes compte aussi pour la sécurité : les couches de raisonnement cachées sont précisément la surface d'attaque ciblée par l'injection de prompt, où des instructions malveillantes contournent entièrement la chaîne de raisonnement visible. Ce phénomène est directement pertinent pour la question de la fiabilité des agents IA : un agent capable de détecter quand son raisonnement a été altéré est intrinsèquement plus robuste.
Ce que cela implique en pratique
Ces découvertes ont trois implications concrètes pour les déploiements IA :
-
L'évaluation doit aller plus loin que les sorties. Si la chaîne de pensée visible est une narration après coup, tester les sorties seules ne permet pas de voir ce que le modèle a réellement "décidé". Les frameworks d'évaluation robustes doivent tenir compte de cet écart.
-
La transparence est plus difficile qu'il n'y paraît. Un modèle qui semble expliquer son raisonnement ne vous montre pas nécessairement son raisonnement réel. Cela est crucial dans les applications réglementées ou à forts enjeux.
-
La capacité introspective est un outil de sécurité émergent. Des modèles capables de détecter quand leurs propres représentations ont été altérées pourraient devenir une couche de défense significative contre les manipulations adversariales.
À mesure que les modèles progressent, ces capacités de raisonnement caché et d'introspection vont probablement croître, posant des questions fondamentales sur la transparence, la confiance et la façon dont nous évaluons l'intelligence artificielle.
✔ Audit gratuit de votre déploiement IA actuel
✔ Architecture conçue pour la transparence et la fiabilité
✔ Suivi et monitoring continus inclus
Réserver un créneau gratuit →
Sources
- Raisonnement latent : Chen, X. et al. (2025). Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning. arXiv:2505.16782. Lire l'article
- Conscience introspective : Lindsey (2025). Emergent Introspective Awareness in Large Language Models. Transformer Circuits. Lire l'article