From Chaos to Control: A 2-Phase Playbook for Bulletproof LLM Evaluations
I was recently deep in a project building an AI-powered feature for a booking platform. The goal was simple: a user types in a query, and our system, guided by a series of LLM prompts, returns a perfect list of relevant options. In development, everything worked beautifully. We crafted our prompts, tested them, and the results were impressive.
But the moment we moved to production, we hit a wall. A developer pushed what seemed like a harmless prompt tweak, a tiny change designed to fix one small issue. Instead, it silently broke three other critical use cases. The whole system suddenly felt incredibly fragile. Welcome to the chaotic, non-deterministic world of LLM development, where "it works on my machine" means very little.
 The two-phase evaluation loop: offline safety net before launch, continuous monitoring in production.
The two-phase evaluation loop: offline safety net before launch, continuous monitoring in production.
That experience forced us to build a robust LLM evaluation strategy from the ground up. Here is the two-phase system we developed to move from chaos to control, ensuring our LLM features are both powerful and predictable.
Phase 1: The Pre-Launch Safety Net (Offline Evaluation)
Before your application ever sees a real user, you need to build a strong safety net. Traditional software unit tests, which expect one exact output for a given input, do not work here. An LLM can produce many valid, slightly different answers. So how do we test for "correctness" when it is so subjective?
The key is building a curated test dataset.
Your first step should always be to manually create a core set of high-quality examples. Do not worry about volume at this stage — focus on quality over quantity (10 to 20 cases). This initial set is your ground truth. A high-quality, hand-crafted dataset ensures your automated CI tests are meaningful and will not trigger false alarms for acceptable variations.
This foundational set should cover:
- Common use cases: The most frequent types of inputs you expect.
- Critical edge cases: Tricky situations or inputs that have caused issues in the past.
- Known failure points: Scenarios you specifically want the model to handle correctly.
Once you have this solid foundation, you can explore synthetic data generation to expand coverage. But understand that synthetic data will closely resemble the patterns of your hand-crafted set — if your initial examples are flawed, synthetic data will only amplify those flaws. Start with quality, then scale with quantity.
This dataset becomes the foundation for your LLM unit tests. By integrating these evaluations into your CI/CD pipeline, you automatically test every change to your model, prompt, or parameters. You can measure accuracy, check for regressions, and even use an LLM-as-a-judge to score the quality of outputs. Every time a prompt is changed, these tests run automatically, acting as your LLM unit tests. The main techniques:
- Pattern Matching: For outputs that need to follow a specific format — a required keyword, a valid JSON object, a correctly formatted URL — this is a fast, reliable check.
- LLM-as-a-Judge: For more subjective checks, use another LLM as an impartial evaluator. In this pre-launch phase, its job is to compare the model's output against the "golden" reference answer from our dataset. We can ask the judge: "Given the user's query and the reference answer, does the model's new output meet the same requirements? Answer YES or NO." This helps us score correctness beyond simple pattern matching.
This offline process is your first line of defense, catching prompt regressions and structural issues before they reach users. It is also where LLM sycophancy becomes a real risk: a model that bends its reasoning to produce plausible-sounding outputs will pass naive tests but fail real use cases — which is precisely why golden-answer comparison matters.
Phase 2: Watching in the Wild (Online Evaluation)
Once your application is deployed, the real learning begins. Your users will interact with your system in ways you never anticipated. This real-world data is gold.
Online evaluation means continuously monitoring your application's performance in production. This does not mean manually checking every output. Instead:
- Capture traces: Log the inputs, outputs, and intermediate steps of your LLM-powered system.
- Run batch evaluations: On a daily or weekly basis, evaluate a sample of recent user interactions to check for regressions or quality shifts.
- Use heuristics: Automatically flag interesting data points. Runs that took unusually long, or received negative user feedback, are prime candidates for review.
Two powerful techniques for this phase:
- Semantic Similarity: This is crucial for measuring relevance. We can automatically compare the user's input (e.g., "a quiet hotel in Paris for a honeymoon") against the model's output (the descriptions of the hotels it suggested). A low semantic similarity score might indicate the model is drifting off-topic or hallucinating, allowing us to flag that interaction for review.
- LLM-as-a-Judge: With no golden answer to compare against, use a rubric instead: "On a scale of 1 to 5, rate helpfulness. Did the response follow our safety guardrails? Was the tone appropriate?" Confidence levels (Low / Medium / High) often work better than numerical scores for consistency.
This continuous monitoring powers A/B testing of different prompts or models and ensures your application keeps improving after launch. It is especially critical when working with AI agents in production: the more autonomous the system, the more essential continuous monitoring becomes.
You do not need to build all of this from scratch. Platforms like Langfuse (open-source) and Arize AI (enterprise-scale) provide the infrastructure to capture traces, debug issues, and automate LLM observability workflows.
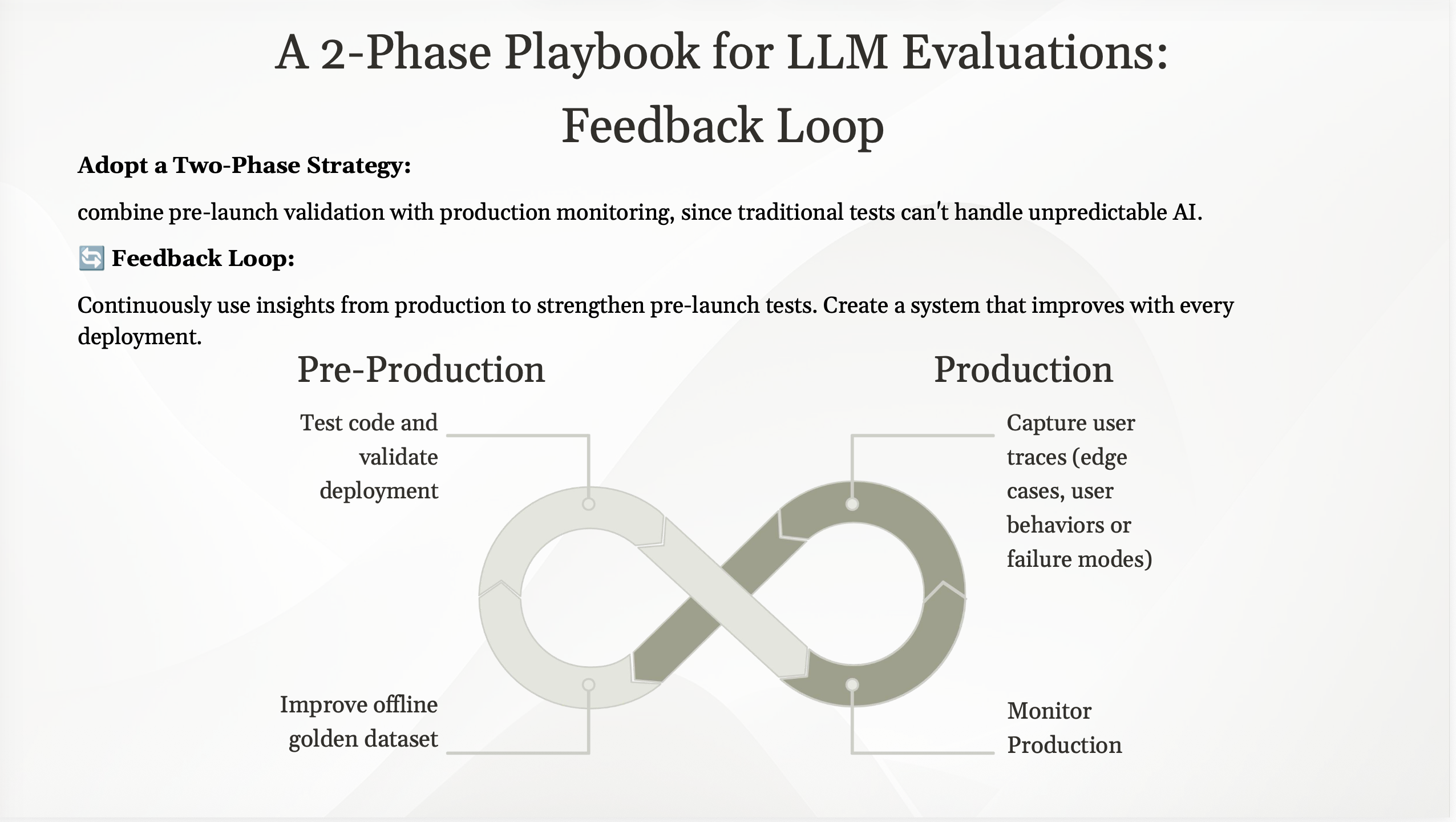
A Continuous Feedback Loop
Offline and online evaluation are not separate stages. They form a continuous cycle:
- Develop and Test: Build and validate prompts against your offline, curated dataset.
- Deploy: Ship your feature to users.
- Monitor and Capture: Analyse real-world user data through online evaluation.
- Enrich and Refine: Identify new edge cases and failure modes from production data.
- Add to Offline Data: Expand your ground-truth dataset with real-world failures and restart the cycle.
This loop ensures your evaluation strategy stays relevant as your users and use cases evolve. The best frameworks test behaviour across many inputs, not just individual outputs.
The teams that build sustainable LLM features are not the ones who ship fastest. They are the ones who instrument their systems early, learn from production, and iterate with data.
✔ Evaluation strategy designed alongside your AI feature
✔ Offline test datasets and CI integration included
✔ Production monitoring and alerting from day one
Book a free slot →