Du chaos au contrôle : un framework en 2 phases pour évaluer vos LLMs
Je travaillais récemment sur un projet d'ajout d'une fonctionnalité IA pour une plateforme de réservation. L'objectif était simple : un utilisateur saisit une requête, et notre système, guidé par une série de prompts LLM, retourne une liste parfaite d'options pertinentes. En développement, tout fonctionnait parfaitement.
Mais dès que nous sommes passés en production, nous avons heurté un mur. Un développeur a poussé ce qui semblait être une modification anodine, un léger ajustement de prompt conçu pour corriger un petit problème. À la place, cela a silencieusement cassé trois autres cas d'usage critiques. Le système entier est soudainement apparu incroyablement fragile. Bienvenue dans le monde chaotique et non-déterministe du développement LLM, où "ça marche sur ma machine" ne veut presque rien dire.
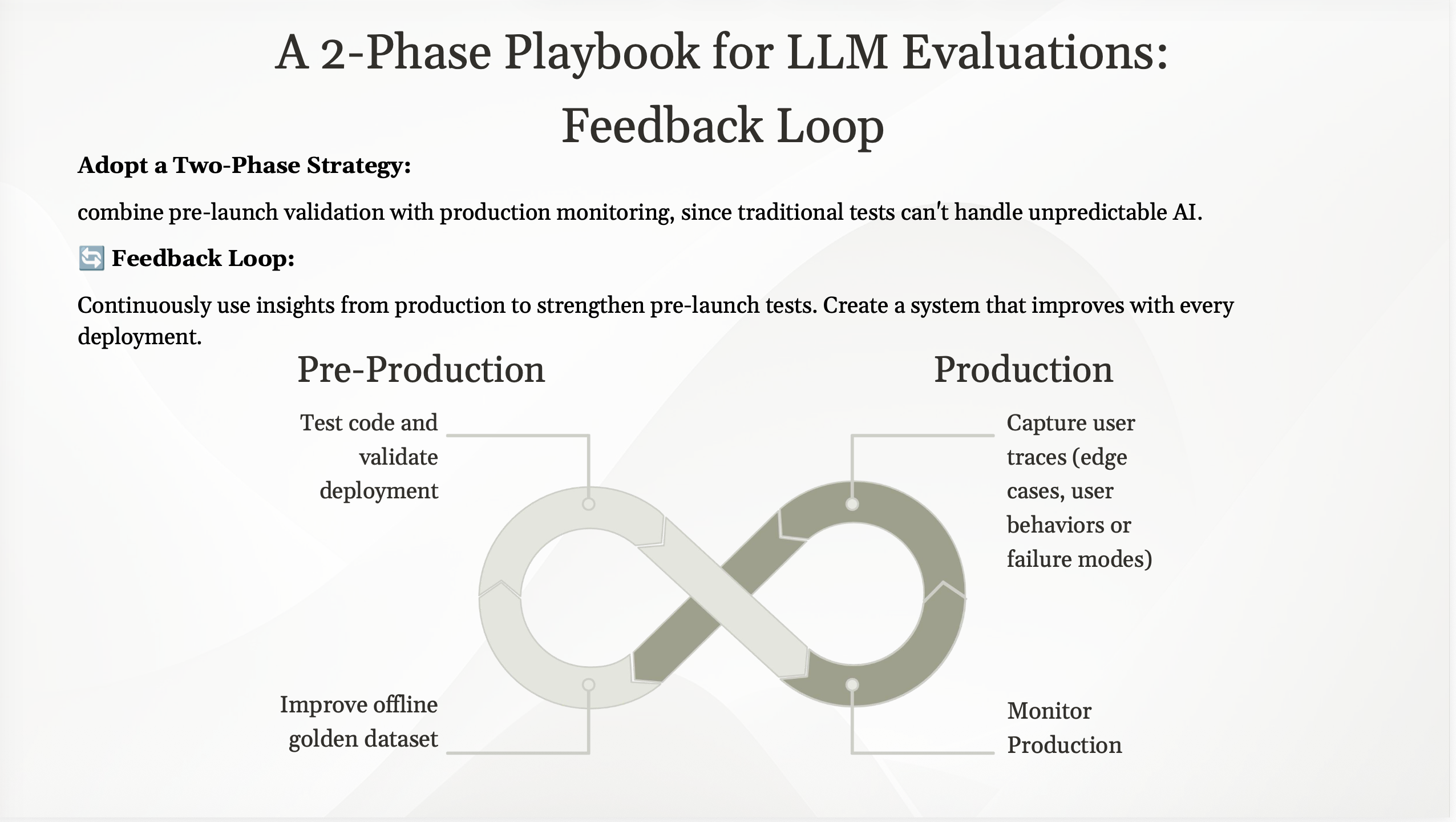 La boucle d'évaluation en deux phases : filet de sécurité hors ligne avant le lancement, surveillance continue en production.
La boucle d'évaluation en deux phases : filet de sécurité hors ligne avant le lancement, surveillance continue en production.
Cette expérience nous a forcés à construire une stratégie d'évaluation LLM robuste depuis le début. Voici le système en deux phases que nous avons développé pour passer du chaos au contrôle, en veillant à ce que nos fonctionnalités LLM soient à la fois puissantes et prévisibles.
Phase 1 : Le filet de sécurité avant le lancement (évaluation hors ligne)
Avant que votre application ne voie un seul vrai utilisateur, vous devez construire un filet de sécurité solide. Les tests unitaires logiciels traditionnels, qui attendent une sortie exacte pour une entrée donnée, ne fonctionnent pas ici. Un LLM peut produire de nombreuses réponses valides et légèrement différentes. Comment donc tester la "correction" quand elle est si subjective ?
La clé est de construire un jeu de données de test soigneusement sélectionné.
Votre première étape doit toujours être de créer manuellement un ensemble central d'exemples de haute qualité. Ne vous inquiétez pas du volume à ce stade, privilégiez la qualité à la quantité (10 à 20 cas). Cet ensemble initial est votre vérité terrain. Un jeu de données de haute qualité, façonné à la main, garantit que vos tests CI automatisés sont significatifs et ne déclencheront pas de fausses alarmes pour des variations acceptables.
Cet ensemble fondamental doit couvrir :
- Cas d'usage courants : les types d'entrées les plus fréquents que vous attendez.
- Cas limites critiques : situations délicates ou entrées qui ont causé des problèmes par le passé.
- Points de défaillance connus : scénarios que vous voulez spécifiquement que le modèle gère correctement.
Une fois cette base solide établie, vous pouvez explorer la génération de données synthétiques pour étendre la couverture. Mais comprenez que les données synthétiques ressembleront étroitement aux patterns de votre ensemble fait main — si vos exemples initiaux sont défectueux, les données synthétiques amplifieront ces défauts. Commencez par la qualité, puis montez en volume.
Ce jeu de données devient le fondement de vos tests unitaires LLM. En intégrant ces évaluations dans votre pipeline CI/CD, vous testez automatiquement chaque changement de modèle, prompt ou paramètre. Vous pouvez mesurer la précision, détecter les régressions, et même utiliser un LLM-as-a-judge pour scorer la qualité des sorties. Chaque fois qu'un prompt est modifié, ces tests s'exécutent automatiquement, jouant le rôle de vos tests unitaires LLM. Les principales techniques :
- Pattern Matching : pour les sorties qui doivent suivre un format spécifique (un mot-clé requis, un objet JSON valide, une URL correctement formatée), c'est une vérification rapide et fiable.
- LLM-as-a-Judge : pour des vérifications plus subjectives, utilisez un autre LLM comme évaluateur impartial. Dans cette phase pré-lancement, son rôle est de comparer la sortie du modèle avec la réponse de référence "dorée" de notre jeu de données. On peut poser au juge : "Étant donné la requête de l'utilisateur et la réponse de référence, la nouvelle sortie du modèle répond-elle aux mêmes exigences ? Répondez OUI ou NON." Cela nous permet de scorer la correction au-delà du simple pattern matching.
Ce processus hors ligne est votre première ligne de défense, détectant les régressions de prompt et les problèmes structurels avant qu'ils n'atteignent vos utilisateurs. C'est aussi là où la sycophanie des LLMs devient un vrai risque : un modèle qui infléchit son raisonnement pour produire des sorties plausibles passera les tests naïfs mais échouera sur les vrais cas d'usage.
Phase 2 : Observer dans la nature (évaluation en ligne)
Une fois votre application déployée, le vrai apprentissage commence. Vos utilisateurs interagiront avec votre système d'une manière que vous n'aviez jamais anticipée. Ces données du monde réel sont précieuses.
L'évaluation en ligne signifie surveiller en continu les performances de votre application en production. Cela ne signifie pas vérifier manuellement chaque sortie. À la place :
- Capturer les traces : enregistrer les entrées, sorties et étapes intermédiaires de votre système LLM.
- Lancer des évaluations par lots : quotidiennement ou hebdomadairement, évaluer un échantillon d'interactions récentes pour détecter les régressions ou les changements de qualité.
- Utiliser des heuristiques : signaler automatiquement les points de données intéressants. Les exécutions anormalement longues ou ayant reçu des retours négatifs sont des candidates idéales pour une révision.
Deux techniques puissantes pour cette phase :
- Similarité sémantique : c'est essentiel pour mesurer la pertinence. On peut automatiquement comparer l'entrée de l'utilisateur (ex. : "un hôtel calme à Paris pour une lune de miel") avec la sortie du modèle (les descriptions des hôtels suggérés). Un faible score de similarité sémantique peut indiquer que le modèle dérive hors sujet ou hallucine, ce qui permet de signaler cette interaction pour révision.
- LLM-as-a-Judge : sans réponse dorée à comparer, utilisez un rubrique à la place : "Sur une échelle de 1 à 5, évaluez l'utilité. La réponse a-t-elle respecté nos garde-fous de sécurité ? Le ton était-il approprié ?" Les niveaux de confiance (Faible / Moyen / Élevé) fonctionnent souvent mieux que les scores numériques pour la cohérence.
Cette surveillance continue alimente les tests A/B de différents prompts ou modèles et garantit que votre application continue de s'améliorer après le lancement. Elle est particulièrement critique avec les agents IA en production : plus le système est autonome, plus la surveillance continue est essentielle.
Vous n'avez pas besoin de tout construire from scratch. Des plateformes comme Langfuse (open-source) et Arize AI (enterprise) fournissent l'infrastructure pour capturer les traces, déboguer les problèmes et automatiser les workflows d'observabilité LLM.
Une boucle de rétroaction continue
L'évaluation hors ligne et en ligne ne sont pas des étapes séparées. Elles forment un cycle continu :
- Développer et tester : construire et valider les prompts sur votre jeu de données hors ligne.
- Déployer : livrer votre fonctionnalité aux utilisateurs.
- Surveiller et capturer : analyser les données utilisateurs du monde réel via l'évaluation en ligne.
- Enrichir et affiner : identifier de nouveaux cas limites et modes de défaillance à partir des données de production.
- Ajouter aux données hors ligne : enrichir votre jeu de données de vérité terrain avec les défaillances réelles et recommencer le cycle.
Cette boucle garantit que votre stratégie d'évaluation reste pertinente à mesure que vos utilisateurs et cas d'usage évoluent. Les meilleurs frameworks testent le comportement sur de nombreuses entrées, pas seulement des sorties individuelles.
Les équipes qui construisent des fonctionnalités LLM durables ne sont pas celles qui livrent le plus vite. Ce sont celles qui instrumentent leurs systèmes tôt, apprennent de la production et itèrent avec des données.
✔ Stratégie d'évaluation conçue avec votre fonctionnalité IA
✔ Jeux de données de test hors ligne et intégration CI inclus
✔ Monitoring et alertes en production dès le premier jour
Réserver un créneau gratuit →